冷知識:木瓜牛奶裡面沒有蝸牛。
如果你很渴的話可以考慮西瓜牛奶。
冷知識:木瓜牛奶裡面沒有蝸牛。
如果你很渴的話可以考慮西瓜牛奶。
讀到 Spike 大大的「請開啟 JavaScript 以繼續搜尋」這篇文章,想起自己陸陸續續加了一些 JS 的功能,卻一直都沒有做 No-JS 的提示詞或替代方案,真是慚愧,只好趕緊來補一下作業了。
問題:
調整成:
問題:
調整成:
其實這個修改也會有點擔心濫用的問題,原本 API 網址是藏在 JS 檔案裡,爬蟲要自己解析才拿得到。
但是現在補上純表單的方式感覺更容易會被爬蟲抓到,可能以後真的遇到了再說吧,反正再怎麼樣也有審核功能先頂著,之後要換新的 API 網址也不是太麻煩。
其實中間還有修一個大問題,就是萬一留言失敗的時候,頁面上也會顯示成功......如果你曾經有留言過,卻遲遲沒有出現在留言簿上面的話,非常抱歉 QQ
關掉 JS 之後,我才發現原來 Cloudflare 會自動幫我把 Email 替換成「[email protected]」,這是防垃圾信的功能,靠 JS 還原真實信箱。
這個可以手動關掉,但我這邊選擇留著,並且加上一行提示文字:「contact [at] trashposts [dot] com」。
現在多了伺服器渲染的留言列表,搜尋引擎跟存檔機器人就更容易抓到內容了,也算是多了一層備份?
(不用框架就是會有很多沒考慮周全的地方呢)
結果 Form 版上線第一天就真的遇到垃圾訊息了,直覺意外地準,再想看看要怎麼處理吧~
假日跟家人「四大一小」去桃園 Xpark 玩。
桃園站下車,出站後走路約 10 分鐘抵達 Xpark。











場館不大,大約 90 分鐘就逛完了。
不過逛展倒是其次,主要目的還是陪家人和姪子出來走走。
後來想想,注意力分配的情況大概有幾種:
我小時候好像常常會因為這樣而覺得可惜,但年紀漸長後,反而會覺得景點是其次,跟人相處的時光比較珍貴。應該很多人都是這樣吧?
這大概也是為什麼現在越來越多人偏好獨旅?只有這樣,注意力才能完全放回自己身上。
或許也是因為這樣,演唱會我都是自己一個人去的,我才不要在別人面前偷哭勒。(目前聽演唱會的落淚率是 100%,有時候甚至沒什麼哭點,就只是覺得人在現場很不真實而已)
Xpark 外面緊鄰著 Outlet、電影院、美食街。出來的時候餐廳全部大爆滿,最後跑去吃瓦城。← 很沒創意
排隊期間有個小插曲,姪子炸屎噴到我的手臂上。據他父母所說,這是第一次出現這種狀況,看來我也是挺幸運的。
寫到一半跑去看 Xpark 的 Wiki 頁面,發現裡面有隻企鵝叫「Tomorin」,我完全不知道,也就是說我無視了燈?
嗯,好哦。(← 這個人沒看過 MyGO!!!!! ← 每次都要去查有幾個驚嘆號 ← 這是人數的意思嗎?)
阿根廷有點意思,我還真沒看過大家這麼極端厭惡同一支球隊的,而且還是國家隊。
難得當一次黑粉,請假熬夜看比賽,結果還真如了願。
美好的一天 for hate-watchers!


Inspired by Martin Schuhmann.
Introduce yourself with five albums that have shaped you.
— 5 Albums
看到格友的文章,才發現節奏天國出新作了!?
我之前玩過的是《大家的節奏天國》,當時真的是印象深刻,非常好玩。
新作肯定是要支持一下的,查了一下,網路上不少通路的實體版竟然比數位版還便宜,那當然是買實體版囉,畢竟這才算是擁有遊戲嘛(有轉讓、賣掉的價值)。
私心希望可以出電腦版(永遠不可能),用機械鍵盤玩起來還是比較舒服一點,真心搞不懂 Switch 右手拇指會卡到蘑菇頭的神奇設計。
話說回來,當初的《大家的節奏天國》好像也是直播時觀眾朋友(湯包叔?)推薦給我的,甚至後來重玩時的 VOD 現在也還看得到。

目前玩了前十首,體感上覺得難度與複雜度大概只有《大家的節奏天國》的 50% 左右。可能是配合現代人的遊戲習慣吧,做得比較新手友善、好上手一點。
只是這樣一來,打出「一級棒」的時候就沒那麼有成就感了...(還是說我變強了!?)
但還是很好玩啦,而且這次可是足足有 80 首,現在就下結論的話還太早了啦。
總之,100% 推薦。
最近吃到 7-11 出的「日式雞蛋沙拉」三明治,號稱是「日本直輸的蛋沙拉」。
好吃,原來這才是蛋沙拉!
我想差別應該是在「馬優內紫」吧?據說日本用的是蛋黃,台灣用的則是全蛋。
原來我沒吃過蛋沙拉。
炎炎夏日,說到超商冷麵,除了中華涼麵、冷義大利麵之外,大概就是蕎麥麵了吧。
不過按照格友的標準,我也是沒吃過蕎麥麵的。
BUT!烏龍麵倒是有,我家附近有丸龜製麵!
冷知識時間:
中島美雪在 1980 年發行的專輯中,有首歌叫做《蕎麥屋》,歌曲是以蕎麥麵店作為背景。但是在歌詞中,她一邊流著眼淚、一邊吃的其實是「狸貓烏龍麵(たぬきうどん)」哦!
其實,只要點一碗「湯烏龍麵」,再到配料區撒上大量的炸麵衣與蔥花,就是「狸貓烏龍麵」了!
等等,也就是說,蕎麥麵店通常也會有烏龍麵!?
或者反過來說,烏龍麵店是不是也會有蕎麥麵!?
嗯,查了一下台灣的丸龜,沒有。🫠
既然如此,那我只好繼續吃我的台式蕎麥麵了。
畢竟,我還是偏向屬於喜歡「適當自縛」或「刻意保持無知」的那一派嘛。
哦,對啊,我只是想講這個(沒人在乎的)冷知識才寫這篇的。
還是這邊直接拿去投稿?


新發現的有趣看板:「/r/AmItheAsshole/」
發文者通常會以「AITA (Am I the Asshole)」起頭來問問題,回文者則是會用以下幾點來回應:
有時候真的會不知道自己是不是 asshole 呢,當局者迷嘛。(我是看到這篇老文章入坑的)
最近有點想把「部落格分頁」功能砍掉,感覺真的是很無用的功能。
首頁的話也可以斟酌一下,看是要保持全文,還是只放近幾篇的文章連結都可以。
我甚至覺得之前做的這個極簡風還挺不錯的,可以放一些有個性的東西在首頁。
我設定了排程,平日週一到週五,僅開放「早上8點 - 中午12點」可以登入,其它時間會關閉服務。
靈感來自於很久以前用過的平台:「seven39」
唉,「癮」真的是一輩子的課題。🫠
身為 Windows 10 的使用者(公司&個人),有個困擾我許久的問題,就是看不到最新的「小黃臉」。
尤其是出現頻率很高的「融化的臉 🫠」,我通常都需要複製到 Google 去查才知道意思。
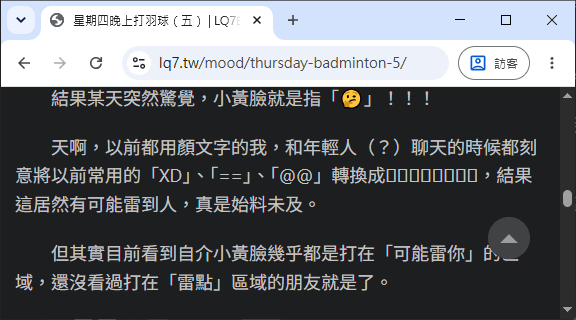
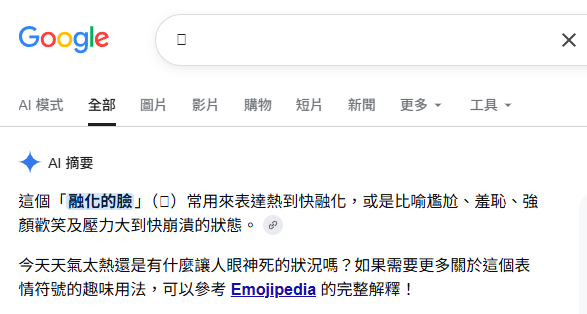
好在今天查到了一個簡單的解法:只要安裝「Emoji Swap」這個瀏覽器套件就可以了。

↑ 是說我覺得 Apple 的「融化的臉」比較有意境,Google 跟 Facebook 的完全沒有那個神韻。
至少目前這個套件有支援到 Twitter 的 Twemoji,還可以接受啦。

好好吃,營養成分也還不錯,就是鈉含量稍微高了一點。
我發現自己在很多日常場合,會下意識做出一些莫名其妙的「假動作」,來避開與別人的交集。
「走進 7-11 想買個麵包,但麵包區已經有人了」
這時我不會湊過去,也不會在旁邊斜眼偷瞄,而是會假裝去看別的東西,等他走掉之後再默默地逛回來。
「正準備過馬路,發現有一台車跟我的路線重疊」(他照常開過去也不會影響到我的時候)
這裡的選項很多,像是正常走、慢慢走、小跑步、招手示意等,但我通常會選最莫名其妙的那個:假裝自己沒有要過馬路。
我會停下腳步,把頭轉到另一個方向假裝在找人,或者拿出手機來划,等他開走後我再悠悠哉哉地走過去。
「前面有點距離的人要進門或進電梯」
如果我不趕時間的話,我會假裝走很慢,或走到對方視線的死角,暗示對方不用等我。
這樣就可以避免被對方幫忙撐著門或電梯了。
前面三點可能是 I 人才會遇到的無聊煩惱,但這點應該是許多男性真實會遇到的情況了:
「在夜間走路時,發現前面有位女性跟自己走同一個方向」←超怕被當成跟蹤狂
這題我的解法是:
有時候好不容易走到岔路,結果發現還是走同一個方向,真的是會很崩潰。
這樣講可能是有點誇張了,基本上只要遵守「保持一定的距離」並且「不要走在同一個直線上」就不會有太大的問題了。
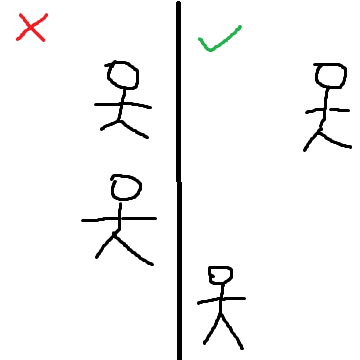
跟風一下〈大人字體〉:

今天晚餐吃三媽臭臭鍋,外送點了兩鍋三個人分著吃。
點餐的時候,我順手翻了一下歷史訂單,想說看看之前都點什麼鍋。
結果上面寫「5月10日」、「5月31日」,嗯?上個月應該只有吃過一次吧,不寫年份誰知道是哪一年。
我就想說乾脆把原始資料抓下來好了,順便可以統計看看我在熊貓上到底都花了多少錢。
結果......

完整報告請看連結:「Foodpanda 消費分析」
真是太恐怖了,我竟然花了 33 萬在叫外送。
雖然說這些金額大概是 2-4 人份的,但累計下來還是有點驚人!(被抓到沒在記帳)
餐廳食物的部份每年都差不多,還算可以預期,倒是生鮮雜貨的比例越來越高。
其中最常消費的就是全聯福利中心了。
因為全聯是「店內價」,也就是現場買跟外送是一樣的價格,甚至偶爾還會有折扣。外送員直接把雜貨送到山上,直接省去了開車、停車的時間,其實還是挺不錯的。
至於餐廳外送的部分,以後確實可以多斟酌一下。
其實很常是因為幫大家一起點,才比較不會去注意價格......(以下省略 200 字藉口)
其實以前有了原始資料後,通常都可以玩個兩三天,慢慢把資料清理、統整,最後把整理完的資料用 Excel 或 HTML 呈現出來。
但現在有了欸哀之後,在等餐的期間,來回互動個幾次就可以完成 80% 了,反正只是一時興起,想看個大概而已。(後面就只是再修一些無關緊要的小細節,比如:加上圖表、分店合併、平均金額等等)
以前搞這種沒意義有趣的東東,通常都會進入心流狀態。只是現在心流狀態從 2 天變成 2 小時,寫程式變成寫自然語言了。是也沒什麼不好啦,只是剛好小聊一下區別。
至於省下來的時間嘛,剛好可以拿去看上禮拜買的小說 XD
(啊,還可以水一篇文章)
是說應該有人讀完會疑惑說 AI 有沒有讀到我的敏感資料?
有,雖然說主要是叫它寫 Python 腳本,然後在本地跑程式去讀資料,所以理論上它只有讀一部分的資料而已。
總之,大家不要像我一樣耍白痴亂餵私人資料哦。
拜託 Claude 半夜不要來我家敲門請我喝茶。
不過,它好像本來就知道我家在哪,我的帳單地址、IP、footprinting 等等資料早就......(請停止碎念下去)